为了更好地学习pytorch,同时大佬榕也推荐了这个比赛,就拿这个比赛练手。经过2个月左右的奋斗(划水),比赛结束了,成绩是34/96。不是一个很好的成绩,但是也不是一个很差的成绩。这次主要是对这次的比赛做个总结,总结经验,为后面的比赛做一个预备吧。
这次比赛是由三个人小队组成,我,大佬榕和小许。我是队长,写了所有的pytorch代码,负责模型的训练。大佬榕和小许负责了数据集的下载。数据的下载花费了几个星期,同时训练模型也花了一个多月时间。
比赛的内容
首先讲下这个比赛的内容,是产品的细粒度的图像分类任务。什么是细粒度分类?细粒度图像分类任务中,有一些大类别,每个大类别底下还有小类别。小类别之间的差异比大类别之间的差异更加细微。在imaterialist-product-2019中,主要有4层类别,第一层共有5类,然后第二层有45类,第三层大约有百来类,最后一层则共有2019类。所有的类别的具体名字不知道,只有一个代名字,最后一层则有类别的标号。
具体的类别信息在:
数据集的信息
类别总共是2019类。
训练样本总数是:1,004,360
验证集样本总数是:10,095
测试集样本总数是:90,834
其中训练集的图片有缺失,验证集也有。测试集没有。
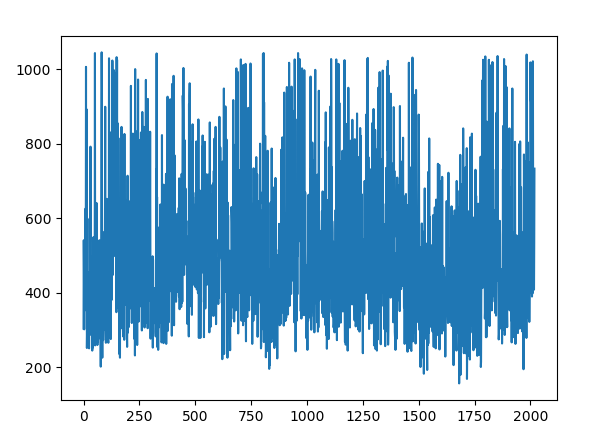
训练集中,每个类样本数最多的有 1045 ;最少的有: 157 ;
样本个数的分布图为:
对于验证集合,所有的类别个数都为5个。样本个数分布图为:
可以看出训练样本集中各个类的样本数量相差很大,多的上千个,而少的一百来个,样本不均衡这个问题是一个需要解决的问题。
环境
一台带titan Xp的windows 10 机子,pytorch1.0
分类模型
采用的分类模型主要有:resnet(resnet50,resnet101,resnet161),densent(densenet161),其最好的性能列表如下:
| model | top-1 | top-5 |
|---|---|---|
| resnet50 | 59.7 | 86.25 |
| resnet101 | 61.4 | 87.2 |
| resnet161 | 59.5 | 85.7 |
| densenet161 | - | 87.56 |
后来使用了model average的方法(其中使用了一些非最佳的模型),大概集成了8个model得到了一个最好的验证精度90.585938
训练过程的细节
数据集预处理
去除了下载中出现错误的图片
图像增强
训练:
resize(224)
randomcrop(224,224)
ColorJitter
RandomHorizontalFlip
RandomRotation
normalize
测试(验证):
resize(224)
centorcrop(224)
normalize
数据读取
用pytorch自带的dataloader,pin_memory=True, num_workers=4,batch_size 根据模型的不同,尽量取大的,并将所有的数据集放在SSD中,加快读取。
没有pin_memory 和ssd大概要4个小时一个epoch(resnet50)。
加了这两个设置,大概1.5个小时一个epoch,加速了很多。
但是一般训练一个模型还是需要2天时间(20epoches)。毕竟xp的显存只有11GB,实际中用的最多只能用10GB。
为了节省显存,采用更节约显存的sgd模型。Adam需要保存很多二阶和二阶的梯度信息,同时也没有比SGD好到那里去,因此采用SGD。
优化
所有的模型都使用了pretrained model.
所有的模型训练的epochs都小于20.
优化器:SGD with momentum
学习率调度:SGDR 和CyclicLR(由于采用了SGDR和CyclicLR,lr的一个调度的结果也被我用于集成。参考黄高的论文)
学习率区间评估:lr_find+eye see
大佬的比赛方案
比赛结束了,kaggle上出现了大佬的方案,有以下我没有做到的:
- 采用更好的分类模型SENET
- 考虑使用autoAugment图像增强
- 考虑类的不均衡问题
- 数据集中去除小图片
- TTA
值得一说的处理不均衡问题,我目前了解有三个方法:
- 上采用和下采样;同时pytorch里面也有一个加权采样器;
- 将训练集分成两个部分,第一部分是均衡的样本集合,每个类个数相同,该部分先用于训练模型;第二个部分是训练集剩下的部分,用于finetune上面的模型
- 使用加权loss比如focal loss等。