SGDR paper
学习率schedule最常见的方法是用一个lr,然后每隔几个epoch除以一个数来减少lr。如下图中的蓝色⚪线和红色
的方块线。
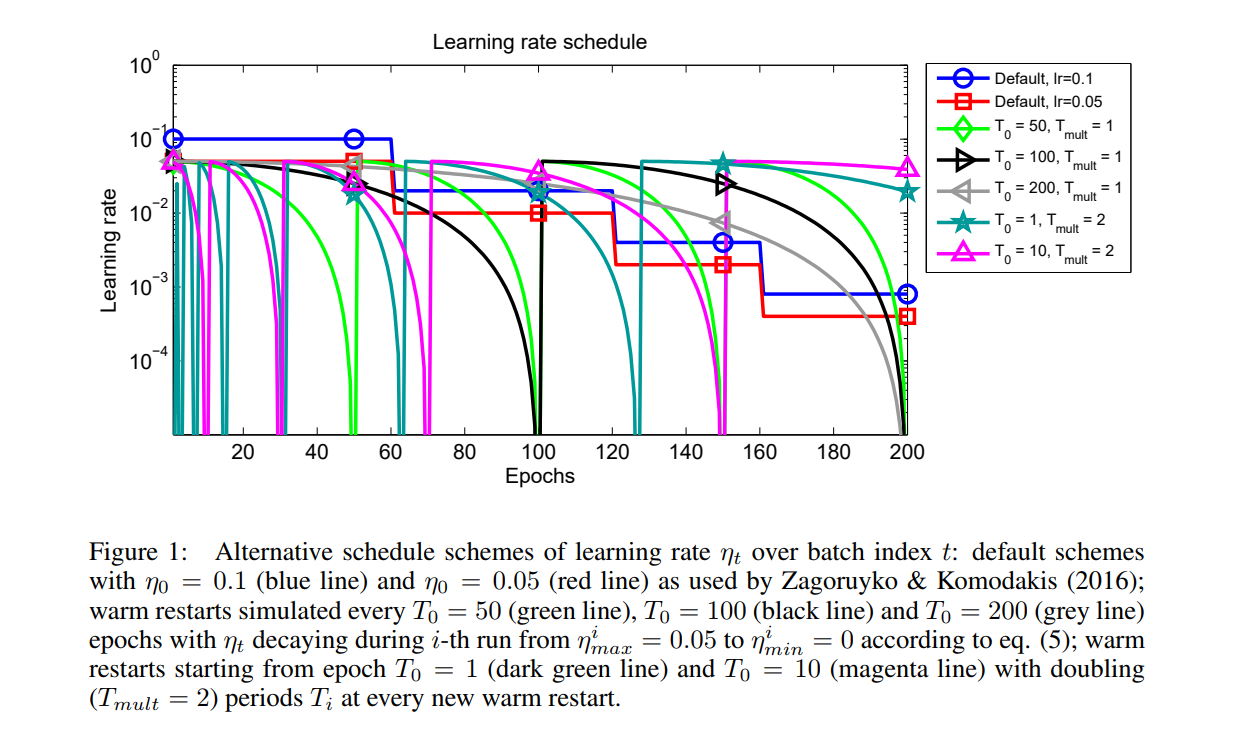
这篇论文所提出的方法是SGD的warm restart版本,即在每次restart,lr都被设置到初始值,但是他的上一次restart到下一次restart之间的距离(schedule)会增加。作者的经验表明,他的这个方法可以比其他的方法快2~4倍达到一个好的效果或者更好的效果。
warm started run SGD T_i 次,其中i是run的index。重要的是,重启不是从头开始执行,而是通过提高学习速率ηt来模拟,而旧的xt值用作初始解决方案
在第i次run,lr decay 是对每个batch用cosine annealing.

图1的绿色线、黑色线和灰色线显示了lr的变化过程。分别固定了$T_i$为50,100,200.
SGDR更进一步选了这么一方法,首先开始的时候$T_i$很小,然后在每次restart都通过乘上一个 $T_{mult}$的因此来提高。例如图一中的暗绿和粉色线。
SGDR in pytorch
pytorch只实现了CosineAnnealingLR,并没有实现restart部分。
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)

它的用法如下:
1 | model = nn.Linear(10, 2) |
实际上,可以通过下面的方式来实现SGDR
1 | model = nn.Linear(10, 2) |
Reference
https://discuss.pytorch.org/t/how-to-implement-torch-optim-lr-scheduler-cosineannealinglr/28797/18
https://pytorch.org/docs/master/optim.html#torch.optim.lr_scheduler.CosineAnnealingLR