paper details
深度学习中有一个常识是,学习率在训练的过程中需要逐渐减小。但是这篇文章却给出了一个让人惊讶的事实,就是训练过程中的学习率如果是多变(rise and fall)的是有益于训练的。因此作者建议学习率在一个范围内周期变化,而不是将其设置为固定值。
Cyclical Learning Rates来源于这么一个观察:学习率的增加虽然会带来短期的副作用但是长期来看是有益的。因此这种观察引出了让学习率在一定范围内变化而不是采用逐步固定或指数递减值的想法。即设置一个最大和最小的边界,然后学习率在里面循环变化。如下图的 triangular learning rate policy:
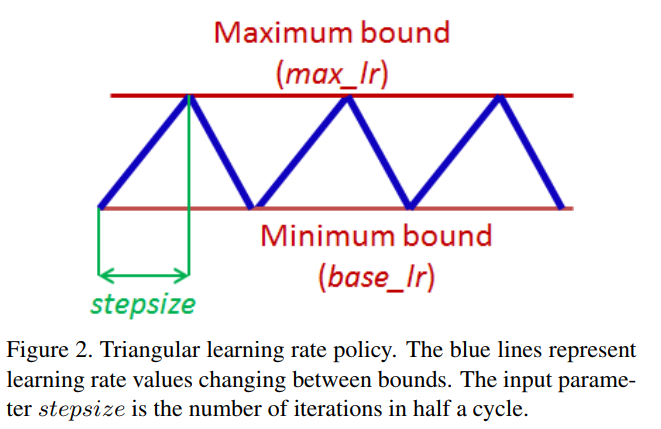
CLR能够发挥作用的一个直观理解是:最小化loss的困难在于如何逃离saddle点而不是在于差的局部最小值。在saddle 点的附近,梯度都很小因此学习的过程缓慢,因此通过增加学习率可以更快地走出saddle点区域。经验上的理由为什么CLR能够work是这样的:最佳的学习率可能在min-max boundaries之间,在最佳的学习率附近会被用于进行训练。(其他会被用于脱离saddle点。。。)。
除了上面显示的trangular learning rate policy,还有以下两种:
triangular2, 和triangular差不多,差别在于每一个cycle之后lr会减半。
exp_range,boundary的值会以一个指数因子衰减。
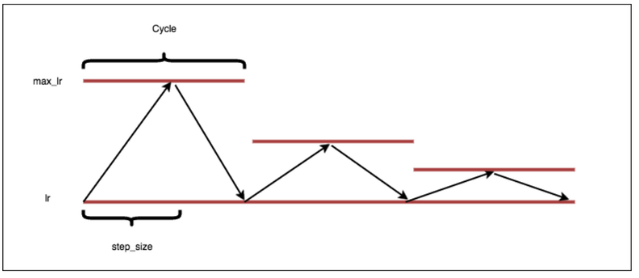
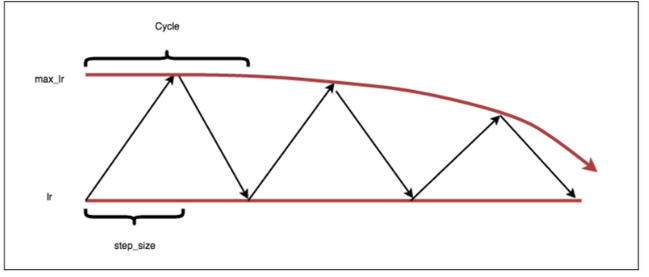
里面还讲了如何去估计一个cycle len的方法:
stepsize最好是2-10倍的每个epoch的迭代次数。对于CIFAR10来说,stepsize=8也就比stepsize=2效果好上一点点。
此外还讲了如何估计一个合理的min和max boundary
第一个方法就是:“LR range test”,模型先跑几个epoch,然后让lr从一个很小值增加到很大的值。然后画出accuracy versus learning rate.如下图:
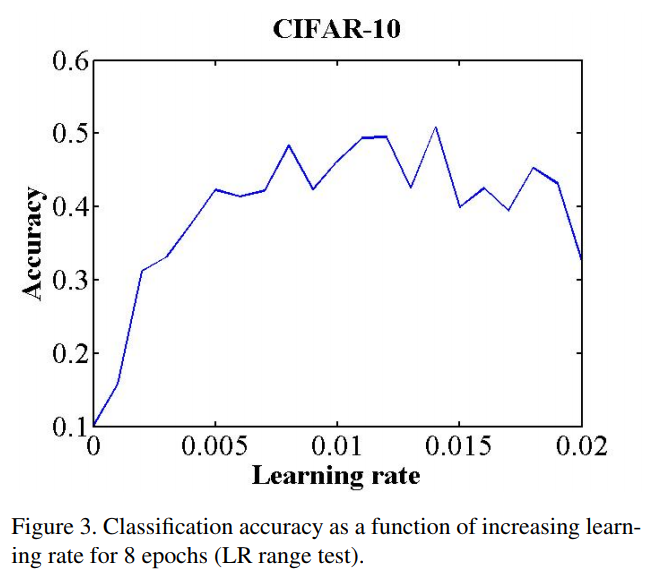
注意图中的accuracy开始增加和accuracy开始变缓的时间段(或者accuracy开始下降)的地方。 这两个地方是bound是的一个好的选择。即base_lr是第一个值,而max_lr是第二个值。或者说可以用一个经验,将base_lr设置为1/3或1/4的max_lr. 论文中作者选了base_lr = 0.001,而max_lr = 0.006
另外一个选择bound是的方法式画出loss versus learning rate的图,如下:
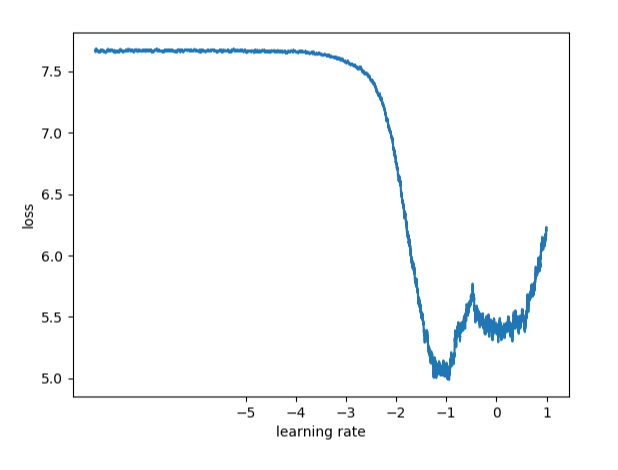
这张图中最适合的lr是哪里?不是在最低点,因为在最低点的lr已经有点大了。我们需要的是一个点更aggressive,所以我们能够train很快。即那个点loss下降是最快的
实验过程
做kaggle比赛的时候,clr的base_lr和max_lr设置反了,特别是在开始的一个stepsize里面,速度非常快,很容易就达到了一个很好的acc ,但是过了这个stepsize,acc就不断下降。一开始举得clclr的问题,后来突然发现是我输入的参数错误。有鉴于它收敛非常快,我觉得还是要借鉴下,发现lr的变化是这样的:
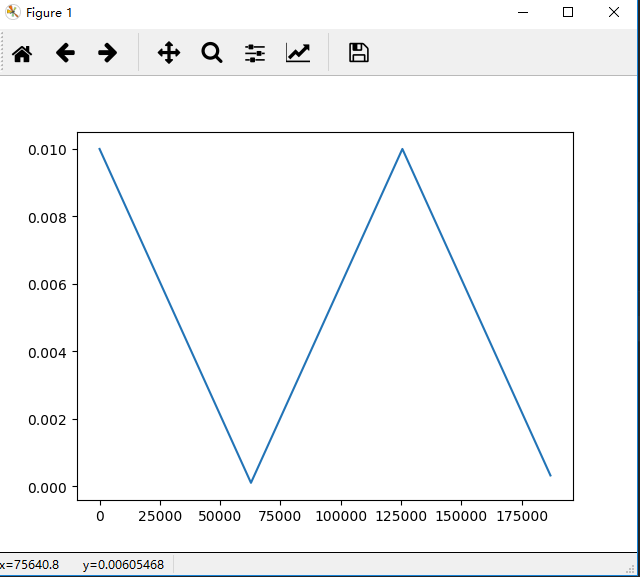
和clr差了一个stepsize。这个和SGDR很相似,准备用这个试试。